Introspective Awareness Demystifies Residual Context
Injected concepts leave detectable residue. Models can detect—and sometimes report—evidence in their own residual stream.
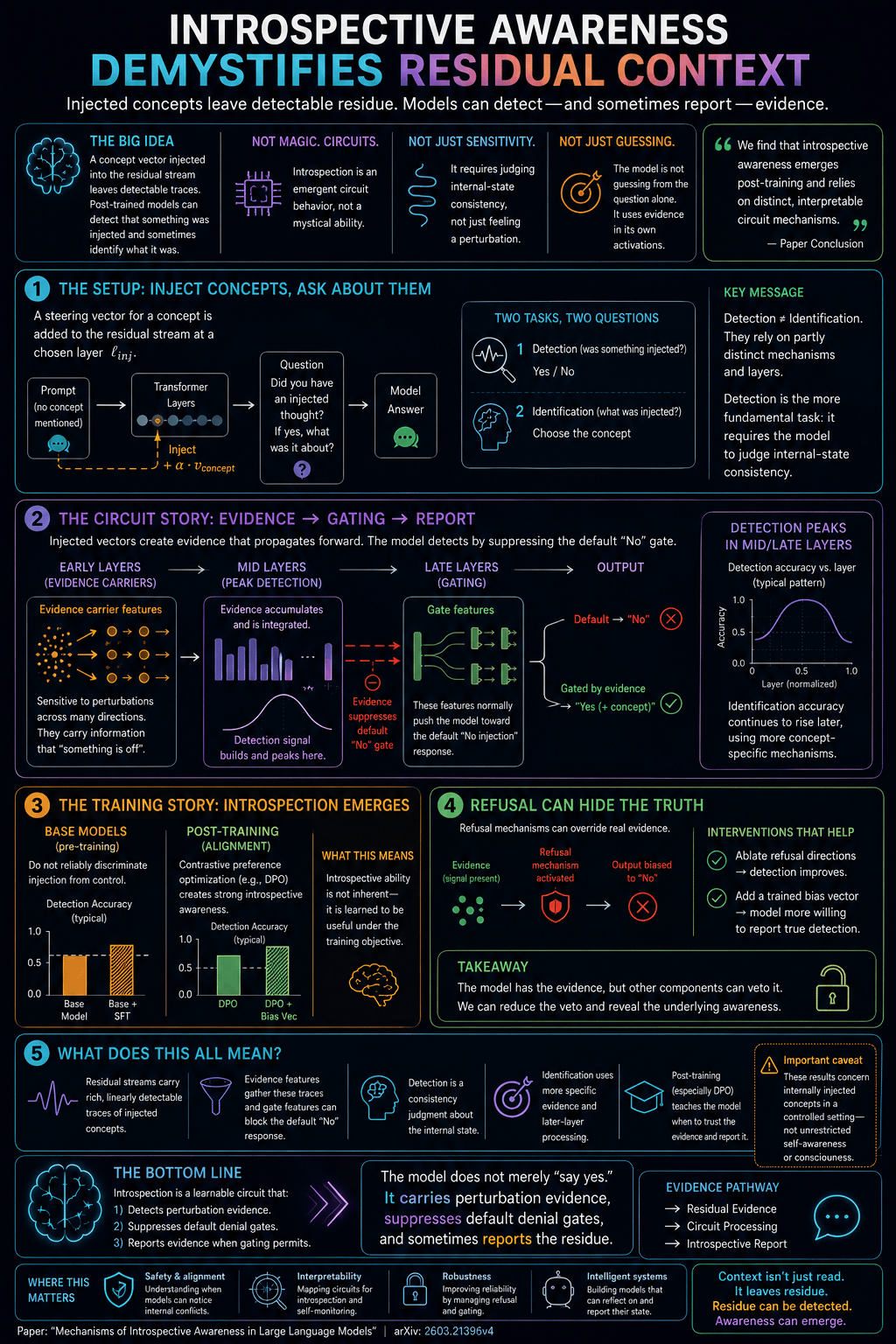
Core claim
Context is not just read. It leaves residue. In this paper, residual-stream concept injections create detectable evidence, and post-trained models sometimes learn to report it.
What the paper studies
The authors inject concept vectors into the residual stream of large language models and ask the model whether an injection occurred and, separately, which concept was injected.
This turns introspection into a controlled circuit-level experiment: detection and identification can be measured rather than merely inferred from self-report.
Detection ≠ identification
Detection asks whether the model notices that its internal state was perturbed. Identification asks whether it can name the injected concept.
The paper argues these rely on partly distinct mechanisms and layers: detection is more about internal-state consistency, while identification uses more concept-specific later processing.
Evidence → gating → report
The circuit story is not mystical. Injected concepts create perturbation evidence, that evidence propagates through layers, and the model reports it when gating permits.
1. Residual evidence
Early post-injection layers contain evidence carrier features that are sensitive to perturbations across many concept directions.
2. Gate suppression
Evidence can suppress default “No injection” gate features that otherwise push the model toward denial.
3. Introspective report
When the evidence pathway wins, the model reports detection and may identify the injected concept.
Why post-training matters
Base models do not reliably distinguish injection from control inputs. Post-training, especially preference optimization, can make models more willing and able to use internal evidence.
This suggests introspective awareness is not an inherent mystical property. It is a learnable behavior shaped by training objectives.
Refusal can hide evidence
The model may carry evidence that something was injected while other components veto the truthful report and bias the output toward “No.”
Interventions such as ablating refusal directions or adding a trained bias vector can increase honest detection in the controlled setup.
Important caveat
These results concern internally injected residual-stream concepts in a controlled experimental setting. They are not evidence of unrestricted self-awareness or consciousness.
Lab-report interpretation
For RML-style work, the paper is valuable because it treats residue as inspectable structure. Residual context is not only stored; it can become evidence for later decisions.
That connects directly to revision triggers, stale-context detection, and models learning when accumulated structure is signal rather than noise.
Citation
Mechanisms of Introspective Awareness in Large Language Models.
arXiv: 2603.21396